


Threat Hunting for AI-Generated Malware: A Practical Framework
Let’s go (threat) hunting today…

Introduction
AI-generated malware, which is crafted and tweaked by large language models, can morph at scale, bypassing signature scans up to 88% of the time, according to a December 2024 security research report. Yes, this report’s a little dated as we’re in May of 2025, but if recent headlines (and substacks) are any indicator, this number is going to increase dramatically over this year.
As this threat landscape evolves, network defenders must lean into behavioral and anomaly-based hunts. I’ve been getting a lot of questions about what to do in the face of this brave (terrifying?) new world that we live in, so I thought it was time to share actionable advice towards addressing a very real threat.
Now, let’s get specific. For today’s post, I’d like to walk y’all through a relevant threat vector of an AI-based threat: polymorphic malware. We’ll be walking through a five-step detection framework, including prerequisites, hypotheses to test, actionable queries, limitations, false-positive mitigation, and prevention measures
This is not meant to be comprehensive, however I do hope that this serves as the first of many steps, so your team can detect and contain AI-powered attacks with confidence.
Threat Landscape & Narrative Walkthrough
Attackers are increasingly turning to AI to supercharge their operations. From WormGPT (a publicly sold LLM for phishing automation) crafting convincing phishing lures to PoisonGPT spreading tailored misinformation, generative models are reshaping the adversary playbook. But perhaps the most insidious use case is polymorphic AI-generated malware, where each build is a unique strain designed to evade static detection.
Why Polymorphism Matters: Traditional signature scanners rely on known hashes or byte patterns. Next-Generation Antivirus (NGAV) solves this problem using machine learning algorithms to analyze files (or operating system behaviors) to tackle new variants in malware or exploit activity. When an AI model tweaks its payload, performing actions like renaming functions, shuffling code blocks, adjusting encryption layers, the signature no longer matches, or the NGAV system mis-classifies the file. Detection drops off a cliff while the malware spreads.
How About An Example?
Walkthrough Example: Imagine a payload called PolyBot, generated by an LLM.
Staging: PolyBot writes dozens of DLL variants (poly_1.dll through poly_20.dll) in a temp folder, where each variant is unique enough to bypass hash-based rules.
Beaconing: Once staged, the loader contacts a fresh C2 domain every 30 seconds to fetch its next instructions.
Phishing Module: PolyBot can send tailored email lures en masse, spinning up a miniature WormGPT instance for social engineering.
Runtime Artifacts: Under the hood, unauthorized TensorFlow scripts decrypt and decompress payload layers on endpoints.
Obfuscation: Finally, each DLL variant is packed to a high-entropy threshold, hiding its true intent from sandbox analyzers.
This end-to-end example underpins why we need behavioral, network, automation, artifact, and entropy-based hunts. Let's break down how each of our five steps catches a piece of the PolyBot lifecycle.
Prerequisites & Technical Setup
Permissions & Access: Read access to endpoint (process, file, entropy), network (DNS, proxy) and email logs in your SIEM/ELK/Splunk.
Tools & Custom Functions:
Entropy: Splunk requires a custom command or scheduled lookup to compute file entropy (calculate_entropy).
Similarity: Jaccard or Levenshtein functions may need a plugin or pre-processing for subject clustering.
Lookups: Nightly WHOIS ingestion into domain_age_lookup (via a WHOIS API) for accurate domain-age data.
Test Environment: Always run queries in a non-production index/environment first to calibrate thresholds.
What the heck is Jaccard or Levenshtein? Great question. Jaccard similarity measures the overlap between two sets, like the shared words in two email subjects, by dividing the size of their intersection by their union, while Levenshtein distance counts the minimum number of single-character edits (insertions, deletions, or substitutions) needed to transform one string into another.
What is entropy? In security, entropy measures the randomness or unpredictability of data. Legitimate files typically have predictable patterns and lower entropy (usually below 7.0), while encrypted or obfuscated malware often has higher entropy (above 7.5) because it appears more random.
Based on prevalence and a desire to keep these queries normalized, I’ve decided to standardize on Splunk’s Search Processing Language (SPL). If you’ve got direct questions about other languages for hunts, let me know!
Let’s Go Hunting
In the context of Polymorphic malware, we’re going to run through five steps that are indicative of polymorphism, AI-generation and broader anomalous activity.
1. Behavior-First Detection: Polymorphic Staging
To start we’re going to ask: “Have any users dropped an unusually large number of distinct files into one directory in a short window?”
Why it works: AI payloads stage multiple, slightly varied files to evade static hashes.
Query:
index=endpoint
| stats dc(file_path) AS file_count by user
| where file_count > 10
| where NOT match(user, "^svc_") AND NOT match(user, "^dev_")
Explanation: Flags users writing >10 distinct files in one directory. We exclude service/dev accounts to reduce noise. In our example environment, normal users write 1 to 3 temp files per hour.
Limitations & False-Positive Mitigation:
Benign installers may appear as a result of running this hunt. To eliminate false positives, I’d suggest excluding known installer paths (e.g., C:\Windows\Installer).
Baseline Tuning: Adjust 10 and 5 based on your org size:
Small (<500 hosts): file_count > 5
Medium (500–2k hosts): file_count > 10
Large (>2k hosts): file_count > 20
2. Network Anomaly Hunting: Beaconing to Fresh Domains
This next step is about understanding if attackers are looking to call back to establish a command and control server. We’re asking “which external domains are our endpoints repeatedly and broadly contacting. Does this pattern look more like C2 beaconing than normal user or application traffic?”
Why it works: AI droppers often call back to newly registered C2 domains.
Query:
index=network (sourcetype=dns OR sourcetype=http)
| stats dc(src_ip) AS host_count count AS req_count by dest_domain
| where host_count > 3 AND req_count > 10
Explanation: Surfaces domains contacted by >2 hosts and registered <7 days ago. This does require up-to-date WHOIS data.
Limitations & False-Positive Mitigation:
DNS Logging: Ensure full DNS logging. If only IPs are logged, add a reverse DNS lookup step.
Legitimate New Services: Monitor first, then block; maintain an allow-list of business-critical domains.
3. Automation Pattern Recognition: AI-Driven Phishing Batches
Next up, phishing. Caveat that this may be noisy if you do any sort of outbound en-masse email sending. Here we're going to ask “which senders are firing off clusters of near‑identical email subjects in rapid succession. Is this behavior more like automated phishing than human‑driven mail?”
Why it works: AI scripts flood inboxes with near-identical emails faster than humans.
Query:
index=email sourcetype=mail Action=MailSend
| transaction sender maxspan=15s maxevents=10
| eval sim = jaccard(subject, mvindex(Subject, -1))
| where sim > 0.85
Explanation: Clusters duplicate emails sent <15 s apart with >85% subject similarity. Exclude known mailing lists to reduce noise.
Alternatives: Use Levenshtein distance or k-means clustering on hashed subjects if Jaccard is unavailable.
4. AI-Tool Artifact Discovery: Rogue Runtimes
Ok now that we’ve got a handle on network and email anomalies, let’s look at the host again. We want to understand which production hosts are spawning more than two AI‑related processes under the same parent. This behavior might look more like an attacker deploying AI toolkits than normal operations.
Why it works: Attackers deploy AI runtimes (Python, TensorFlow) in production environments.
Query:
index=process sourcetype=Sysmon
| where process_name IN ("python.exe","python3","tensorflow.exe")
| stats count AS proc_count by host, parent_process
| where proc_count > 2 AND host_role="production"
Explanation: Flags >2 AI-tool processes on production hosts. Adjust threshold for dev and/or data science hosts.
Limitations & Mitigation:
Incomplete Ancestry: Some EDRs only log process starts; validate parent_process logging.
Dev Exclusion: Filter by host tags (e.g., host_role).
5. Entropy & Obfuscation Indicators
Finally, let’s ask the question “which files on endpoints exhibit unusually high entropy?” This suggests they’re packed or obfuscated, so we can pinpoint potential polymorphic or packed malware for further review.
Why it works: Polymorphic or packed binaries exhibit high entropy compared to standard executables.
Query:
index=endpoint sourcetype=filehashes
| where entropy > 7.5
| stats count by file_path, parent_process
Explanation: Flags files with entropy >7.5. Adjust threshold per your file makeup.
Limitations & Mitigation:
False Positives: Legitimate updaters or packers may appear; maintain an allow-list of known high-entropy binaries.
Combine Signals: Pair entropy checks with file-size anomalies or unusual PE headers.

Prevention & Defense In Depth
While detection is important to your resilience (you can’t stop what you cannot see), couple your hunts with preventive measures:
Code Integrity: Enforce allow-listing (Windows AppLocker, Linux AEP).
Network Controls: Monitor (don't auto-block) new domains, evaluate business needs before blocking.
Email Hygiene: Enforce DKIM/SPF/DMARC and sandbox attachments.
Runtime Protections: Block script execution from temp directories via EDR policies.
While by no means comprehensive, these steps should get the ball rolling in the right direction.
Where do we go from here?
Alright now that we’ve got a handle on PolyBot…what else can we do as network defenders? Here’s a list of suggested next steps:
Cross-Platform Queries:
Use tools like QRadar AQL, Azure Sentinel KQL equivalents.
Org-Size Thresholds: because no two environments are the same. Some helpful benchmarking here.
Small (<500 hosts): thresholds / file_count >5, hosts >1
Medium (500–2k): file_count >10, hosts >2
Large (>2k): file_count >20, hosts >5
SOAR Integration: can be tricky, but if you’ve got a SOAR or are on the path to automation…tools like Palo Alto Networks Cortex XSOAR, Splunk Phantom, Tines: automate containment or enrichment playbooks.
Testing & Validation: run hunts for 7 days in test indexes, and compare to known benign baselines.
Threat Evolution: update this living framework as AI threats adopt new languages (Go-compiled payloads, multi-stage loaders).
Summary Table: Indicators, Queries & Mitigation
Ok so to put this into a TLDR table; here’s a summary for folks:
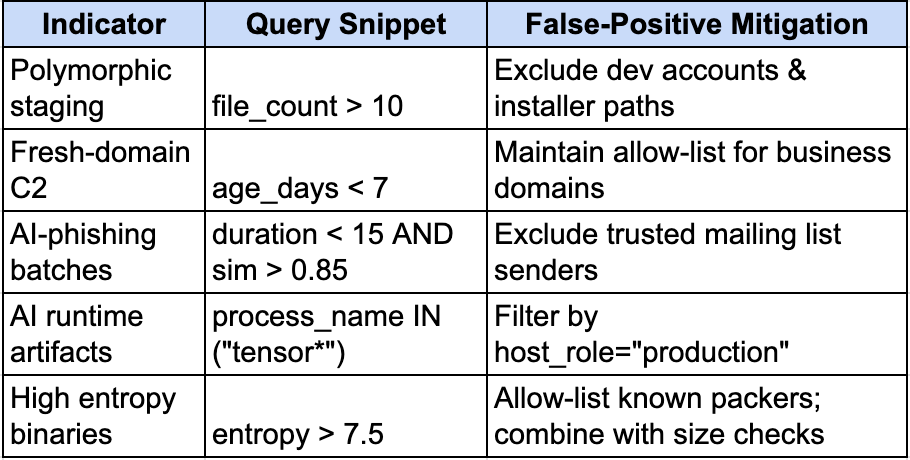
By applying these behavior, network, automation, artifact and entropy-based hunts, matched with prevention controls, we can effectively take steps towards turning the tide on AI-powered threats. Run the queries, tune the thresholds, and consider automation where possible.
These are suggestions, not requirements. If you have found effective ways to find/detect AI-generated malware in your environment, please let me know directly or in the comments. Security is a team sport, so let’s win together.
Stay secure and stay curious my friends!
Damien
Love this write-up! It's incredibly helpful to see the actual queries you'd run at each step of the hunt and the reasoning behind them.
I'm really struck by how complex these behavioral threat hunts can be—and how much expertise is required across different tools and organizational contexts. Thanks for sharing.